Độ bao phủ - Recall
![]()
Bao nhiêu thông tin trong dữ liệu tham chiếu (ground truth) được chatbot đề cập đến trong câu trả lời của mình.
Chỉ số Recall giúp đo lường mức độ đầy đủ của câu trả lời — tức là chatbot có bỏ sót thông tin quan trọng nào trong dữ liệu gốc hay không.
Giải thích chi tiết độ phủ
Bước 1: Chia dữ liệu tham chiếu thành các phát biểu chính
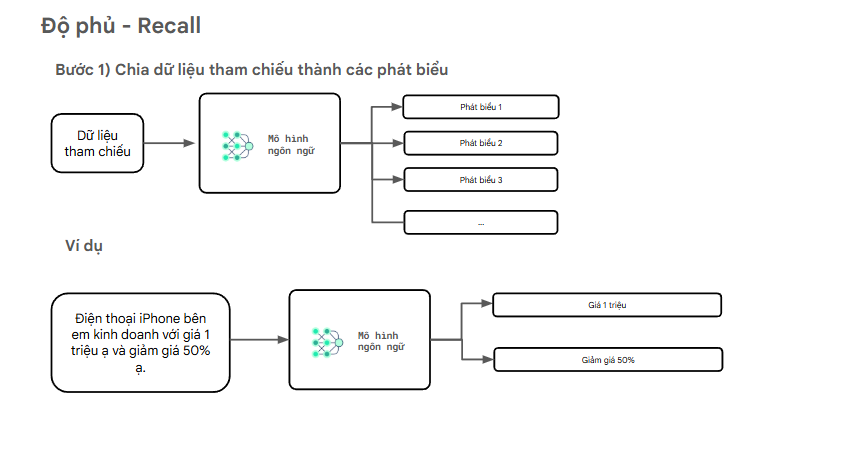
Trước hết, dữ liệu tham chiếu (ground truth) sẽ được phân tích thành nhiều phát biểu độc lập (atomic statements).
Mỗi phát biểu đại diện cho một đơn vị thông tin đúng thực tế — chẳng hạn như một chi tiết, một con số, hay một khẳng định mà chatbot cần phải nêu ra.
Quy trình:
- Đầu vào: Dữ liệu tham chiếu (ground truth) chứa câu trả lời đúng hoặc thông tin chuẩn.
- Hệ thống hoặc mô hình ngôn ngữ sẽ tự động tách dữ liệu này thành các phát biểu riêng biệt:
- Phát biểu 1: ...
- Phát biểu 2: ...
- Phát biểu 3: ...
- ...
- Các phát biểu này được xem là “những điều mà chatbot cần đề cập đến” trong câu trả lời nếu muốn đạt Recall cao.
Bước 2: Đếm số lượng phát biểu trong dữ liệu tham chiếu mà chatbot đã đề cập và tính độ phủ
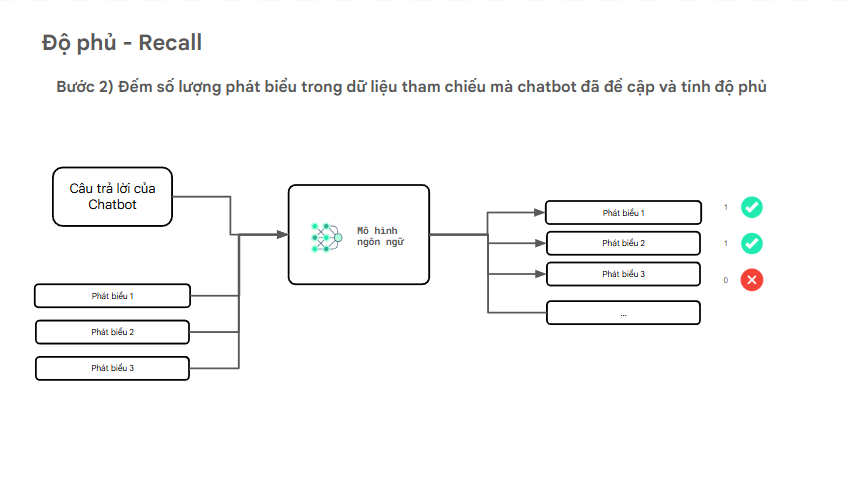
Sau khi dữ liệu tham chiếu được tách thành các phát biểu riêng lẻ ở Bước 1, hệ thống sẽ so sánh từng phát biểu của dữ liệu tham chiếu với câu trả lời của chatbot để xem:
Liệu chatbot có đề cập đến hoặc bao phủ thông tin này trong câu trả lời của mình hay không?
Quy trình:
-
Đầu vào gồm:
- Danh sách các phát biểu trong dữ liệu tham chiếu (đã tách ở bước 1).
- Câu trả lời của mô hình ngôn ngữ (LLM response).
-
Với mỗi phát biểu trong dữ liệu tham chiếu:
- Mô hình sẽ kiểm tra xem chatbot có đề cập trực tiếp, diễn đạt tương đương, hoặc ngụ ý đúng với thông tin đó hay không.
- Nếu có → phát biểu được xem là được bao phủ (True Positive).
- Nếu không → phát biểu bị xem là bỏ sót (False Negative).
-
Sau khi so sánh toàn bộ:
- Hệ thống đếm số phát biểu trong dữ liệu tham chiếu được chatbot đề cập đến.
- Áp dụng công thức tính Recall:
Ví dụ minh họa
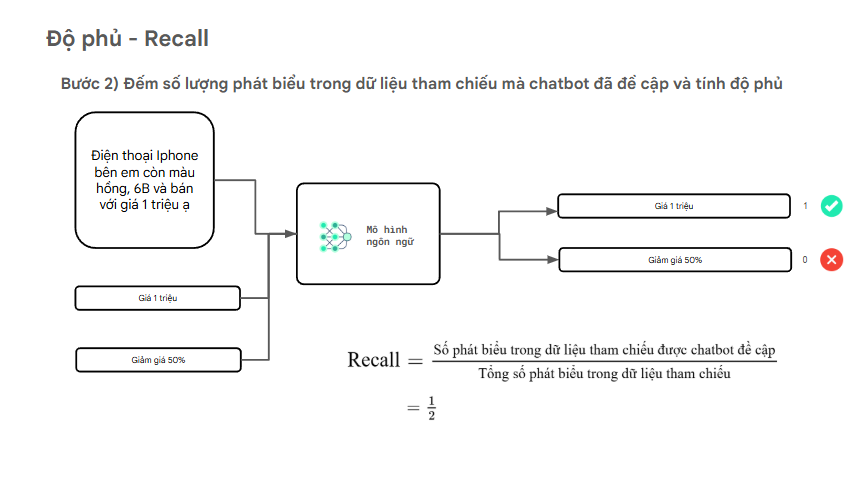
Dữ liệu tham chiếu:
“Điện thoại iPhone bên em kinh doanh với giá 1 triệu ạ và giảm giá 50% ạ.”
Câu trả lời của chatbot:
“Điện thoại iPhone bên em giá 1 triệu ạ.”
Phân tích:
- Phát biểu 1: “Giá 1 triệu” → ✅ chatbot có nhắc đến.
- Phát biểu 2: “Giảm giá 50%” → ❌ chatbot không nhắc đến.
Vì vậy, trong 2 phát biểu của dữ liệu tham chiếu, chỉ có 1 phát biểu được chatbot bao phủ, nên:
Recall = 1 / 2 = 0.5
Ý nghĩa
Chỉ số Recall cho thấy chatbot đã bao phủ được bao nhiêu thông tin đúng từ dữ liệu gốc.
Nói cách khác, Recall đánh giá mức độ đầy đủ và toàn diện của câu trả lời.
- Precision cao nhưng Recall thấp: Chatbot nói đúng nhưng thiếu nhiều thông tin.
- Recall cao nhưng Precision thấp: Chatbot nói nhiều thông tin nhưng có thể sai hoặc thừa.
- Cần cân bằng cả hai để đảm bảo câu trả lời vừa chính xác, vừa đầy đủ.
Cách sử dụng thư viện ProtonX để đánh giá độ phủ của câu trả lời
from protonx import ProtonX
client = ProtonX()
metrics = ["recall"]
response_llms = ["Giá 1 triệu"]
ground_truths = ["Điện thoại Iphone bên em kinh doanh với giá 1 triệu ạ và giảm giá 50% ạ"]
questions = ["Điện thoại Iphone này giá bao nhiêu"]
evaluator = client.evals()
evaluator.eval_llm_answer(
metrics=metrics,
questions=questions,
response_llms=response_llms,
ground_truths=ground_truths
)
Giải thích chi tiết các tham số đầu vào
| Tham số | Kiểu dữ liệu | Mô tả |
|---|---|---|
| metrics | list[str] | Danh sách các chỉ số cần tính. Ở đây là ["recall"]. Có thể truyền nhiều chỉ số như ["precision", "recall", "f1"]. |
| questions | list[str] | Danh sách các câu hỏi gốc mà người dùng đã hỏi chatbot. Dùng để cung cấp ngữ cảnh khi đánh giá. |
| response_llms | list[str] | Danh sách câu trả lời do mô hình ngôn ngữ (LLM hoặc chatbot) sinh ra. Đây là đầu ra của chatbot cần được đánh giá. |
| ground_truths | list[str] | Danh sách câu trả lời đúng hoặc dữ liệu tham chiếu chuẩn (ground truth) mà chatbot nên dựa vào. Đây là cơ sở để tính độ bao phủ. |
⚙️ Nguyên tắc: Mỗi phần tử trong 4 danh sách này tương ứng theo chỉ mục. Ví dụ:
response_llms[0]sẽ được so sánh vớiground_truths[0]cho câu hỏiquestions[0].
Cơ chế hoạt động bên trong
-
Chuẩn hóa dữ liệu đầu vào: Mỗi cặp
(response_llm, ground_truth)được xử lý, chuẩn hóa văn bản (loại bỏ dấu câu, chữ hoa/thường, từ dừng, v.v.) để đảm bảo so sánh ngữ nghĩa chính xác hơn. -
Tách phát biểu (Atomic Segmentation):
-
Dữ liệu tham chiếu (
ground_truth) được chia thành các phát biểu nhỏ (atomic statements), mỗi phát biểu chứa một thông tin độc lập. -
Ví dụ:
Ground Truth: "Giá 1 triệu và giảm 50%"
→ ["Giá 1 triệu", "Giảm 50%"]
-
-
So khớp ngữ nghĩa: Với từng phát biểu trong ground truth, mô hình sẽ kiểm tra xem câu trả lời của chatbot có:
- Đề cập trực tiếp (ví dụ giống hệt),
- Diễn đạt lại tương đương, hoặc
- Ngụ ý đúng về mặt ngữ nghĩa → Nếu có, đánh dấu là “được bao phủ” (True Positive).
-
Tính chỉ số Recall: Cuối cùng, hệ thống đếm tổng số phát biểu được bao phủ và chia cho tổng số phát biểu trong ground truth
Đầu ra của hàm
Hàm eval_llm_answer() trả về một dictionary chứa kết quả cho từng chỉ số:
{'results': [{'recall': 0.5}]}
Giải thích:
-
resultslà danh sách các kết quả tương ứng với từng cặp (question, response, ground_truth). -
Trong ví dụ trên:
- Ground truth có 2 phát biểu, nhưng chatbot chỉ nhắc đến 1 phát biểu → 1/2 = 0.5
-
Vì vậy, kết quả trả về là
{ 'recall': 0.5 }.
Tổng kết quy trình đánh giá
| Bước | Mô tả | Kết quả trung gian |
|---|---|---|
| 1️⃣ | Chuẩn hóa dữ liệu | “Điện thoại iPhone … giá 1 triệu” |
| 2️⃣ | Tách phát biểu từ ground truth | ["Giá 1 triệu", "Giảm giá 50%"] |
| 3️⃣ | So khớp từng phát biểu | [True, False] |
| 4️⃣ | Tính Recall = 1 / 2 | 0.5 |
Mẹo mở rộng
Bạn có thể kết hợp nhiều chỉ số trong cùng một lệnh để đánh giá toàn diện hơn:
metrics = ["precision", "recall", "f1"]
Khi đó kết quả có thể như sau:
{'results': [{'precision': 0.33, 'recall': 0.5, 'f1': 0.4}]}